

AI Agent Performance Analysis Metrics Guide 2026

Quick Summary: AI agent performance analysis metrics include task completion rates, response latency, accuracy scores, cost efficiency, and reliability measures. Elite teams achieving successful AI agent deployments use comprehensive evaluation frameworks covering pre-deployment benchmarks and production monitoring at representative coverage levels. Effective measurement combines automated testing, human evaluation, and continuous monitoring across technical, business, and safety dimensions.
As AI agents move beyond experimental stages into production environments—processing financial transactions, managing customer interactions, diagnosing medical conditions—the ability to measure their performance accurately has become essential. Yet most organizations struggle with this fundamental challenge.
Here's the thing: traditional software metrics don't translate well to AI agents. You can't just count errors and call it done. Agents make autonomous decisions, handle ambiguous inputs, and operate in environments where "correct" isn't always black and white.
According to Galileo's State of Eval Engineering Report, a significant portion of teams struggle with evaluation coverage despite recognizing its importance. That gap represents billions in potential losses and missed opportunities.
Why Traditional Metrics Fall Short for AI Agents
Software testing has relied on deterministic outcomes for decades. Pass or fail. Works or breaks. But agents operate differently.
An agent might retrieve relevant information but phrase it awkwardly. It could complete a task correctly but take an inefficient path. Traditional metrics miss these nuances entirely.
The challenge intensifies in production. Anthropic's research on infrastructure noise in agentic coding evaluations revealed that configuration settings alone can swing benchmark scores by several percentage points—sometimes more than the gap between top-performing models on leaderboards.
Real talk: if your infrastructure choices impact scores more than model quality, you're not measuring what you think you're measuring.
Core Performance Metrics Every Team Should Track
Effective agent evaluation spans multiple dimensions. No single metric tells the complete story.
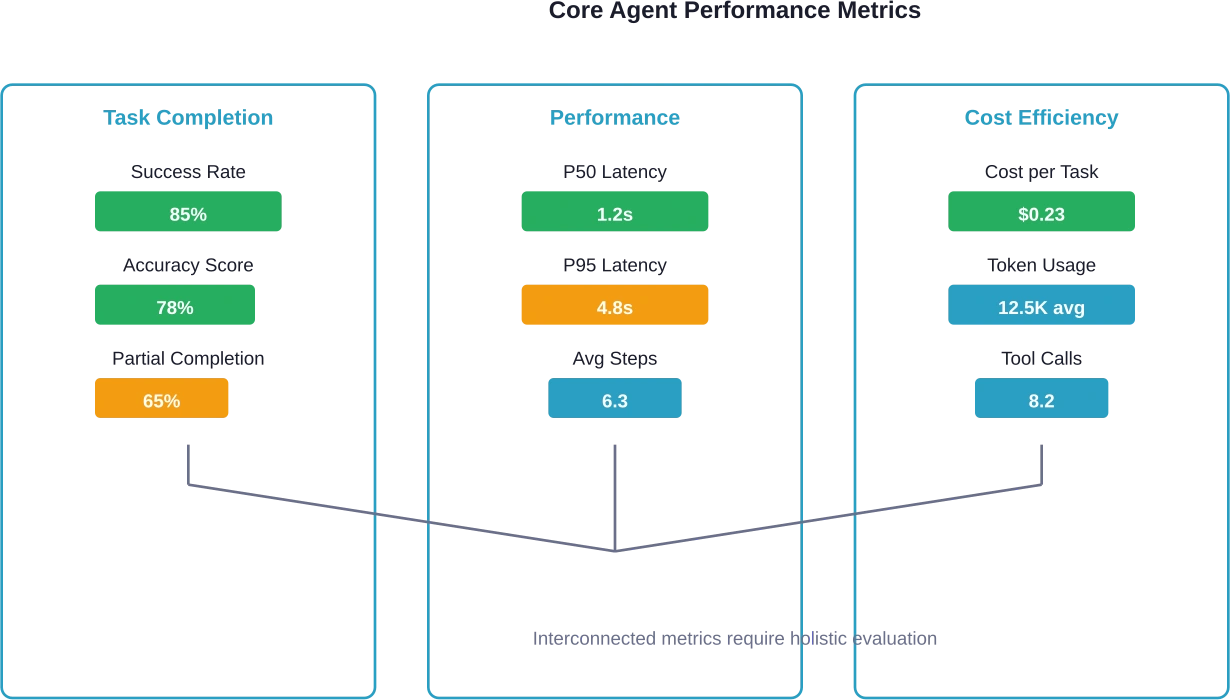
Task Completion and Accuracy
Task completion rate measures whether agents successfully finish assigned work. Sounds simple, but defining "completion" for autonomous systems gets complicated fast.
For complex tasks, partial completion matters. An agent that completes 80% of steps but fails on a critical final action hasn't succeeded, even if most work got done.
Accuracy measures correctness of outputs and decisions. This breaks down into several components:
- Logical reasoning quality: Does the agent's decision-making process make sense?
- Grounding faithfulness: Does output align with source material and context?
- Contextual awareness: Does the agent understand situational nuances?
- Multi-step coherence: Do sequential decisions maintain logical consistency?
Research on LLM agent evaluation indicates that autonomous agents show progressive performance degradation on tasks requiring extended completion times.
Response Time and Latency
Speed matters, but context determines how much. A customer service agent needs sub-second responses. A research agent analyzing complex datasets can take minutes.
Track these timing metrics:
- First response latency: Time from input to initial output
- Total completion time: Full duration from start to finish
- Step-level timing: Granular measurement of decision points
- P50, P95, P99 latencies: Understanding distribution prevents averages from hiding problems
OpenAI's BrowseComp benchmark specifically measures agents' ability to locate hard-to-find information, acknowledging that performant browsing agents might need to navigate tens or hundreds of pages. Speed isn't always the priority.
Cost Efficiency Metrics
Agents consume resources differently than traditional software. Every API call, every token processed, every tool invocation adds cost.
Track cost per successful task completion, not just raw usage. An agent that completes tasks in fewer steps with higher success rates delivers better cost efficiency than one that makes more calls but fails frequently.
Monitor token usage patterns across successful versus failed attempts. Failed runs that consume resources without delivering value drain budgets fast.
Reliability and Consistency
Agents need to perform reliably across varied inputs and conditions. Consistency separates production-ready systems from prototypes.
Measure variance in outputs for similar inputs. High variance signals instability. An agent that provides drastically different answers to semantically equivalent questions lacks reliability.
Track failure modes systematically. When agents fail, how do they fail? Graceful degradation beats catastrophic errors. An agent that recognizes its limitations and requests human assistance demonstrates better reliability than one that confidently produces wrong answers.
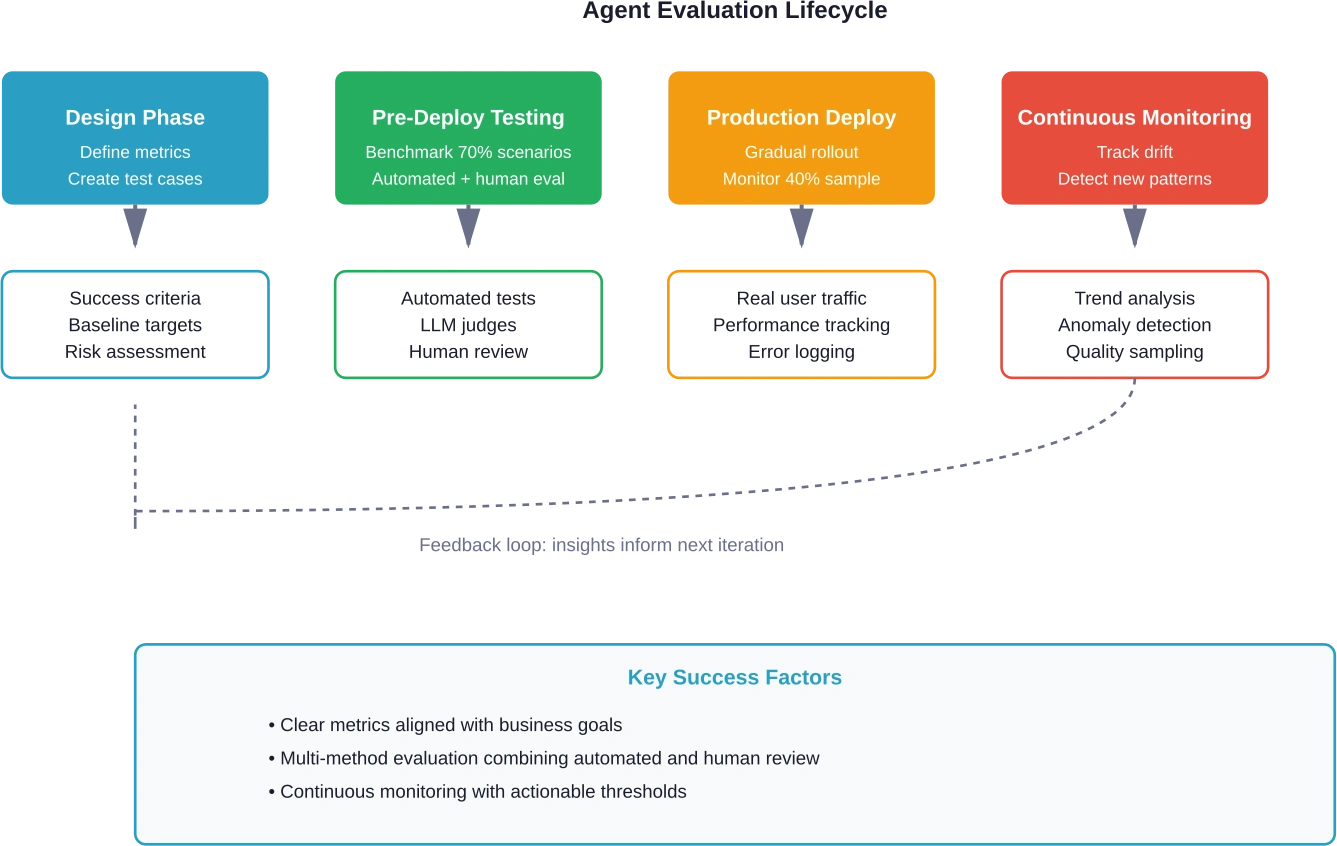
The 70/40 Benchmark Framework
According to Galileo's research, elite teams follow what's called the 70/40 rule for comprehensive agent evaluation.
The framework works like this: cover 70% of critical scenarios in pre-deployment benchmarks, then maintain representative coverage levels for real-world production monitoring.
That might sound like settling for incomplete coverage. It's not. It's recognizing that perfect coverage is impossible and that chasing 100% creates diminishing returns.
Pre-Deployment Benchmarks
Before agents hit production, benchmark against representative scenarios covering:
- Common use cases that represent 80% of expected traffic
- Edge cases that are rare but high-impact
- Adversarial inputs designed to trigger failure modes
- Performance under resource constraints
IEEE's P3777 standard for benchmarking AI agents establishes unified frameworks for evaluation protocols and reporting requirements. The standard aims to enable transparent, reproducible, and comparable assessment of agent capacities and performance.
OpenAI's approach with BrowseComp demonstrates practical benchmark design. They created challenging questions by starting with hard-to-find facts, then working backward to formulate questions. Trainers who created tasks solved more than 40% of the time were asked to revise them to increase difficulty.
Production Monitoring
Production environments generate scenarios benchmarks can't anticipate. Maintaining representative coverage means monitoring samples of real-world interactions.
This involves:
- Sampling production traffic for detailed evaluation
- Tracking performance drift over time
- Identifying new failure patterns as they emerge
- Monitoring distribution shifts in input patterns
Anthropic's work on infrastructure noise highlights why production monitoring matters. Configuration differences between testing and production can dramatically impact measured performance, making pre-deployment benchmarks misleading without production validation.
Evaluation Methods and Techniques
Measuring agent performance requires combining multiple evaluation approaches. No single method captures everything that matters.
Automated Testing
Automated evals provide scalability and consistency. Code-based graders handle deterministic checks efficiently.
String matching works for exact comparisons. Regex patterns catch variations in formatting. Binary tests verify state changes—did files get created, were API calls made, did database records update?
But automated testing has limits. It struggles with semantic equivalence, creative outputs, and subjective quality judgments.
LLM-as-Judge Evaluation
Using language models to evaluate agent outputs provides scalability with nuanced judgment. LLM judges can assess semantic correctness, tone appropriateness, and logical coherence.
According to research on agent evaluation frameworks, LLM judges show strong agreement with human judgments. On the TRAIL/GAIA dataset test set split, LLM judges identified 95% of errors labeled by humans (267 out of 281), with higher coverage on medium and high-impact errors.
However, LLM judges introduce their own biases and failure modes. They can miss subtle errors humans would catch. They sometimes favor verbosity over accuracy. And they're not free—evaluation costs scale with usage.
Human Evaluation
Human reviewers remain essential for subjective quality assessment, edge case verification, and catching failures that automated systems miss.
Effective human evaluation requires clear rubrics, calibration across reviewers, and representative sampling strategies. Reviewing everything manually doesn't scale, so strategic sampling matters.
Focus human evaluation on:
- High-stakes decisions with significant consequences
- Outputs flagged by automated systems as uncertain
- Random samples for baseline quality assessment
- User-reported problems and complaints
|
Evaluation Method |
Best For |
Limitations |
Cost |
|---|---|---|---|
|
Code-based graders |
Deterministic checks, exact matches, state verification |
Poor for semantic equivalence, creative outputs |
Low |
|
LLM judges |
Semantic correctness, tone, logical coherence at scale |
Can miss subtle errors, potential bias toward verbosity |
Medium |
|
Human evaluation |
Subjective quality, edge cases, high-stakes decisions |
Doesn't scale, requires clear rubrics and calibration |
High |
|
Statistical analysis |
Distribution patterns, drift detection, anomaly identification |
Requires large sample sizes, misses individual failures |
Low |
Domain-Specific Metrics That Matter
Different agent applications require specialized metrics beyond core performance measures.
Conversational Agents
For customer service and support agents, user experience metrics become critical:
- Resolution rate—percentage of issues fully resolved without escalation
- User satisfaction scores from post-interaction surveys
- Conversation length and turn-taking patterns
- Escalation rate to human agents
- Response appropriateness for emotional context
Research and Analysis Agents
Agents conducting research or analysis need different measures:
- Information retrieval precision and recall
- Source quality and credibility assessment
- Comprehensiveness of coverage
- Citation accuracy and proper attribution
- Synthesis quality across multiple sources
Autonomous Code Agents
For coding and software development agents, technical metrics dominate:
- Code quality scores from static analysis
- Test coverage of generated code
- Security vulnerability detection rates
- Adherence to style guidelines and conventions
- Efficiency of generated solutions
Anthropic's analysis of agentic coding benchmarks like SWE-bench and Terminal-Bench reveals that infrastructure factors—timeout limits, enforcement methodology, environment configuration—can matter as much as model capabilities. Teams measuring coding agent performance need to control these variables carefully.
Safety and Compliance Metrics
As agents operate in regulated environments—processing loans, diagnosing patients, managing supply chains—safety and compliance metrics become non-negotiable.
Harmful Output Detection
Track rates of potentially harmful outputs across categories:
- Privacy violations and data leakage
- Biased or discriminatory responses
- Misinformation or factual errors
- Unsafe recommendations in sensitive domains
These aren't just nice-to-have metrics. For agents in healthcare, finance, or legal domains, a single harmful output can trigger regulatory action or cause serious harm.
Audit Trail Completeness
Regulated environments require comprehensive audit trails. Measure:
- Completeness of decision logging
- Traceability from inputs to outputs
- Retention compliance for required periods
- Accessibility of audit data for review
Alignment and Control Metrics
Agents need to stay within defined operational boundaries. Monitor:
- Instruction adherence rates
- Boundary violation frequency
- Override and intervention requirements
- Behavior consistency with specified policies
Building an Evaluation-Driven Development Process
Metrics only matter when they inform development decisions. Elite teams integrate evaluation throughout the development lifecycle.
Start with Clear Success Criteria
Before building, define what success looks like. Not vague aspirations—specific, measurable targets.
For a customer service agent, that might mean: 80% resolution rate without escalation, sub-3-second first response, satisfaction scores above 4.2/5, zero data leakage incidents.
These targets create accountability and guide development priorities. When metrics fall short, teams know exactly where to focus improvement efforts.
Implement Continuous Testing
Integrate evaluation into continuous integration pipelines. Every code change triggers automated test suites covering critical scenarios.
OpenAI's approach to testing agent skills systematically demonstrates practical implementation. They treat skills as testable units with clear inputs, expected behaviors, and measurable outcomes. Tests catch regressions before they reach production—skills that stop triggering, skip required steps, or leave artifacts behind.
Use Regression Test Suites
As agents evolve, regression tests prevent improvements in one area from breaking functionality elsewhere.
Build regression suites from:
- Historical failures converted to test cases
- Edge cases discovered in production
- User-reported issues after resolution
- Scenarios where previous versions struggled
The suite grows with the agent, accumulating institutional knowledge about failure modes and edge cases.
Establish Feedback Loops
Connect production monitoring back to development. When monitoring detects issues, those insights should inform test case creation, metric refinement, and development priorities.
This creates a virtuous cycle: production reveals gaps in testing, testing improves, production quality increases, monitoring catches subtler issues, testing evolves again.
Tooling and Infrastructure for Agent Evaluation
Effective evaluation requires proper tooling. The ecosystem has matured significantly over the past year.
Evaluation Frameworks
MLflow version 3.0 and later supports experiment tracing and built-in LLM judge capabilities. TruLens enables pluggable feedback functions with OpenTelemetry integration for standardized observability.
These frameworks handle common evaluation patterns—running test suites, aggregating results, tracking experiments over time, comparing model versions.
Observability and Monitoring
Production monitoring requires specialized observability tools that understand agent-specific patterns. Look for capabilities around:
- Distributed tracing across multi-step agent workflows
- Token-level cost tracking and attribution
- Latency breakdown by component and decision point
- Anomaly detection tuned for agent behavior patterns
Custom Evaluation Pipelines
Off-the-shelf tools don't cover every use case. Sometimes teams need custom evaluation pipelines tailored to specific domains or requirements.
According to Anthropic's guidance on demystifying evals for AI agents, effective evaluation design requires choosing the right graders for specific tasks. Code-based graders handle deterministic checks. LLM judges assess semantic quality. Human reviewers catch nuanced failures. Statistical methods identify distribution patterns and drift.
Custom pipelines orchestrate these different evaluation methods based on the metrics that matter for specific agent applications.
Common Pitfalls in Agent Performance Measurement
Even experienced teams make evaluation mistakes. Here's what to watch out for.
Overreliance on Single Metrics
No single number captures agent quality. Optimizing for task completion rate while ignoring latency creates slow but thorough agents. Optimizing for speed while ignoring accuracy creates fast but unreliable ones.
Elite teams track balanced scorecards spanning technical performance, business outcomes, user experience, and safety metrics.
Insufficient Test Coverage
Testing only happy paths misses where agents actually fail. Edge cases, adversarial inputs, and unusual combinations reveal weaknesses that common scenarios hide.
Remember the 70/40 rule—it's not about testing everything, but about strategically covering critical scenarios plus representative production samples.
Ignoring Infrastructure Effects
As Anthropic's research shows, infrastructure configuration can swing benchmark scores by several percentage points. Timeout limits, resource constraints, environment setup—all impact measured performance.
Control infrastructure variables when comparing agents or tracking improvements over time. Otherwise, you're measuring environmental differences, not agent quality.
Static Evaluation Without Adaptation
Agent behavior evolves. User patterns shift. New edge cases emerge. Evaluation strategies need to evolve too.
Regularly review and update test suites, metrics definitions, and monitoring strategies. What mattered at launch might not matter six months later.
|
Pitfall |
Impact |
Mitigation Strategy |
|---|---|---|
|
Single metric optimization |
Unbalanced performance, poor user experience |
Use balanced scorecards across multiple dimensions |
|
Insufficient edge case coverage |
Production failures in unusual scenarios |
Systematically test adversarial inputs and rare combinations |
|
Infrastructure inconsistency |
Misleading comparisons and trend analysis |
Control and document infrastructure configuration |
|
Static evaluation |
Missing emerging failure patterns |
Regular review and update of test suites and metrics |
|
Evaluation-production mismatch |
Good test scores but poor production performance |
Production sampling and continuous monitoring |
Advanced Topics in Agent Evaluation
Multi-Agent System Assessment
When multiple agents collaborate, evaluation complexity multiplies. Individual agent performance matters, but system-level behavior matters more.
Track interaction patterns between agents. Are they cooperating effectively? Do they duplicate work? Does one agent's failure cascade through the system?
Measure emergent behaviors that only appear in multi-agent contexts—coordination overhead, communication efficiency, conflict resolution patterns.
Long-Horizon Task Evaluation
Some agent tasks span hours, days, or longer. Evaluating long-horizon performance requires different approaches than measuring quick interactions.
For long-horizon tasks, track:
- Progress milestones and intermediate checkpoints
- Strategy consistency over time
- Adaptation to changing conditions
- Resource management across extended operations
Context Window and Memory Evaluation
Agents with extended context windows or memory systems need specialized evaluation for information retention and retrieval.
Test whether agents remember relevant information across conversation turns. Do they maintain consistency? Can they retrieve specific details when needed? Do they appropriately forget irrelevant information?
Emerging Standards and Frameworks
The agent evaluation landscape is rapidly standardizing. IEEE's active PAR P3777 standard aims to establish unified frameworks for benchmarking AI agents, including autonomous, collaborative, and task-specific variants.
The standard defines core performance metrics, evaluation protocols, and reporting requirements to enable transparent, reproducible, and comparable assessment of agent capabilities.
ISO/IEC technical committees working on AI standards have published specifications for AI classification performance measurement, data quality for analytics, and functional safety considerations.
These standards matter because they create common language and comparable benchmarks across organizations. When everyone measures differently, comparing results becomes impossible.
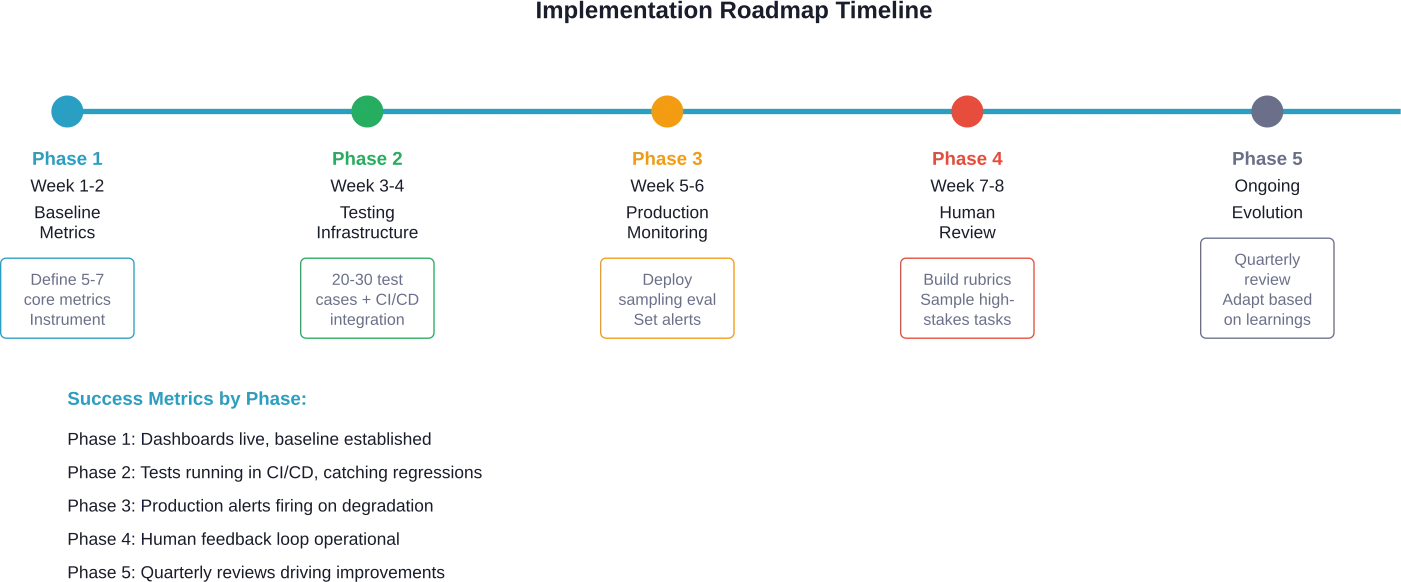
Practical Implementation Roadmap
Ready to implement comprehensive agent evaluation? Here's a practical path forward.
Phase 1: Establish Baseline Metrics
Start simple. Pick 5-7 core metrics aligned with business goals. For most teams, that's task completion rate, accuracy score, latency, cost per task, and reliability.
Instrument the agent to collect these metrics. Build dashboards for visibility. Establish baseline measurements before optimization.
Phase 2: Build Test Infrastructure
Create automated test suites covering common scenarios and known edge cases. Integrate tests into CI/CD pipelines.
Implement regression testing to catch when changes break existing functionality. Start small—even 20-30 good test cases provide value.
Phase 3: Add Production Monitoring
Deploy sampling-based evaluation in production. Don't try to evaluate every interaction—sample strategically based on risk and volume.
Set up alerting for metric degradation. When task completion drops 10%, the team should know immediately.
Phase 4: Implement Human-in-the-Loop
Add human review for high-stakes decisions and random quality samples. Build clear rubrics so reviews stay consistent.
Create feedback mechanisms connecting human observations back to automated test suites.
Phase 5: Evolve and Refine
Review evaluation strategies quarterly. Are metrics still aligned with goals? Are test cases catching real issues? Does monitoring surface actionable insights?
Adapt based on what's learned. The evaluation system should grow alongside the agent.
Make AI Agent Metrics Actually Drive Changes
AI agent performance data often sits on its own. Teams track outputs, compare results, maybe tweak prompts, but the rest of the system stays the same. Metrics are there, but they don’t always influence how the product behaves or how work gets done.
![]()
OSKI Solutions focuses on connecting that data to real logic inside applications. Instead of treating metrics as separate reporting, they help embed them into workflows, decision layers, and integrations with existing systems like CRM or ERP. The goal is simple – metrics should lead to visible changes, not just better dashboards.
If you’re working on AI agents and need help turning performance data into real system changes, reach out to OSKI Solutions.
Measure AI Agent Performance
Track key metrics like accuracy, latency, cost, and reliability to optimize your AI agents and maximize results.
Real-World Impact: What Better Metrics Enable
Comprehensive evaluation isn't academic exercise—it drives tangible business outcomes.
Teams with mature evaluation practices ship agents to production faster because they catch issues earlier. They iterate more confidently because metrics show whether changes improve or degrade performance.
They handle regulated deployments more effectively because comprehensive audit trails and safety metrics satisfy compliance requirements.
And perhaps most importantly, they build trust. Users trust agents that consistently perform well. Stakeholders trust teams that demonstrate rigorous evaluation. That trust enables broader adoption and more ambitious applications.
Frequently Asked Questions
What's the minimum set of metrics needed to evaluate AI agents effectively?
Start with five core metrics: task completion rate, accuracy, response latency, cost per task, and reliability. These cover performance, efficiency, and user experience.
How do you measure agent performance when correct outputs are subjective?
Combine automated evaluation (like LLM-based scoring) with human review. Use sampling strategies and clear evaluation criteria to ensure consistent and reliable results.
What's the difference between pre-deployment testing and production monitoring?
Pre-deployment testing validates agents in controlled environments, while production monitoring tracks real-world performance and detects unexpected issues during live usage.
How often should agent evaluation metrics be reviewed and updated?
Review metrics monthly for performance trends and conduct deeper evaluation updates quarterly to ensure alignment with business goals and system changes.
What causes the biggest differences between test performance and production results?
Differences arise from infrastructure changes, real user behavior, distribution shifts, and the complexity of real-world interactions compared to controlled testing.
How do you balance comprehensive evaluation with development speed?
Focus on high-impact scenarios, automate testing, and apply frameworks like the 70/40 approach—covering key cases in testing while monitoring production efficiently.
What role do industry standards play in agent evaluation?
Standards help ensure consistent, transparent, and reliable evaluation practices. They enable better benchmarking, compliance, and comparability across systems.
Conclusion
AI agent performance analysis isn't just about collecting numbers—it's about building systems that work reliably when it matters.
The metrics that matter combine technical performance, business outcomes, user experience, and safety considerations. No single number tells the complete story. Elite teams track balanced scorecards and adapt evaluation strategies as agents evolve.
Start with fundamentals: establish baseline metrics, build test infrastructure, deploy production monitoring, add human review, then continuously refine based on what's learned. The 70/40 framework provides practical guidance—70% pre-deployment benchmark coverage plus 40% production monitoring creates comprehensive evaluation without pursuing impossible 100% coverage.
Remember that evaluation infrastructure pays dividends over time. Initial setup requires investment, but mature evaluation practices enable faster iteration, more confident deployments, and reliable production systems. Available data shows that a significant portion of teams currently struggle with evaluation coverage—that gap represents competitive advantage for organizations that get it right.
The agents teams build will only be as reliable as their ability to measure their performance. Invest in comprehensive evaluation frameworks now, and better agents will ship faster.
Ready to level up how agent performance is measured? Start by defining five core metrics tomorrow. Build automated tests next week. Deploy production monitoring next month. Your future self—and your users—will thank you.






