

AI Agent Architecture Diagram: Complete Guide 2026

Quick Summary: AI agent architecture diagrams visualize the core components that enable autonomous AI systems to perceive, reason, plan, and act. These diagrams typically illustrate four foundational layers: the LLM reasoning engine, orchestration logic for task management, data infrastructure for memory and state, and tool integration for external interactions. Understanding these architectural patterns helps developers build production-ready agents that balance autonomy with reliability.
AI agents represent a fundamental shift from simple chatbots to systems that can plan multi-step workflows, maintain context across sessions, and interact with external tools. But here's the thing—most architecture diagrams floating around LinkedIn and Medium don't reflect what actually works in production.
According to research published on arXiv (arXiv:2601.19752, submitted January 27, 2026), agentic design patterns require a system-theoretic framework that goes beyond simple prompt engineering. The Agentic Design Patterns paper emphasizes that foundation model-enabled agents need distinguished reasoning and language processing capabilities combined with structured architectural patterns.
This guide breaks down the actual components that power modern AI agents, backed by recent research from arXiv, implementation patterns from Google DeepMind, and practical insights from teams building production systems. No buzzwords. Just the architecture patterns that work.
The Four Foundational Layers of Agent Architecture
Every functional AI agent—whether it's automating web tasks or conducting scientific research—operates across four distinct architectural layers. These aren't arbitrary divisions. They represent the separation of concerns that makes agents maintainable, debuggable, and actually useful.
The reasoning layer handles decision-making through the language model. The orchestration layer manages task flow and execution logic. The data infrastructure layer provides memory and state persistence. And the tool integration layer connects agents to external systems.
Let's break down each layer and see how they work together.

Layer 1: The LLM Reasoning Engine
At the core sits the language model—GPT-4, Claude, Gemini, or increasingly specialized open models. This layer doesn't just generate text. It performs chain-of-thought reasoning, evaluates multiple action paths, and generates structured outputs that drive downstream systems.
Research from Google DeepMind on SIMA 2 (published November 13, 2025) demonstrates how advanced models like Gemini can translate language into meaningful action in complex 3D environments. The key insight? The reasoning layer needs to output structured decisions, not just conversational responses.
Effective prompt engineering at this layer includes system instructions that define the agent's role, examples that demonstrate desired reasoning patterns, and output schemas that enforce structured responses. The reasoning engine doesn't work in isolation—it receives context from memory systems and available tool definitions.
Layer 2: Orchestration Logic
Here's where architecture separates hobbyist projects from production systems. Orchestration determines how tasks flow through the agent, how multiple reasoning steps connect, and when to invoke specific tools or sub-agents.
Azure's AI Agent Orchestration Patterns documentation describes fundamental orchestration patterns including sequential, concurrent, group chat, handoff, and magentic patterns. Sequential orchestration chains tasks linearly—perfect for workflows with clear dependencies. Concurrent orchestration parallelizes independent tasks to improve latency.
The group chat pattern enables multiple specialized agents to collaborate on complex problems. Handoff orchestration routes tasks between agents based on expertise. And magentic orchestration uses a central controller to dynamically assign work.
Real talk: most teams overcomplicate this layer. Start with sequential orchestration. Add complexity only when latency or task specialization demands it.
Layer 3: Data Infrastructure and Memory
Agents need memory. Short-term memory maintains conversation context within the current session. Long-term memory stores information across sessions—user preferences, past interactions, learned patterns.
The architecture typically combines several storage mechanisms. Conversation history stays in working memory (limited by context window). Semantic memory uses vector databases like Pinecone or Weaviate for retrieval-augmented generation. Episodic memory logs past actions and outcomes for reflection and learning.
State management becomes critical when agents handle multi-step workflows that span minutes or hours. Systems need to persist intermediate results, track progress through complex workflows, and gracefully handle interruptions or failures.
Layer 4: Tool Integration
This layer connects agents to the external world. Function calling (supported by OpenAI, Anthropic, and Google) provides a structured interface where the model outputs JSON specifying which tool to invoke with what parameters.
Common tool categories include search engines for information retrieval, code interpreters for computation, database connectors for data access, and API clients for external services. The MolmoWeb agent from AI2 (announced March 24, 2026) demonstrates sophisticated tool use by navigating websites and extracting information using only screenshot inputs.
Tool design matters enormously. Each tool needs clear documentation, explicit input schemas, and robust error handling. Tools should be atomic—doing one thing well—rather than monolithic. This makes debugging tractable and enables better reasoning by the LLM layer.
Common Agent Orchestration Patterns Visualized
Orchestration patterns define how agents break down complex tasks, coordinate multiple reasoning steps, and manage interactions between specialized components. These patterns emerged from production deployments across industries, not academic theory.
The Agent Design Pattern Catalogue published on arXiv in May 2024 catalogs architectural patterns specifically for foundation model-based agents, drawing from real-world implementations across domains. Let's examine the patterns that actually matter.
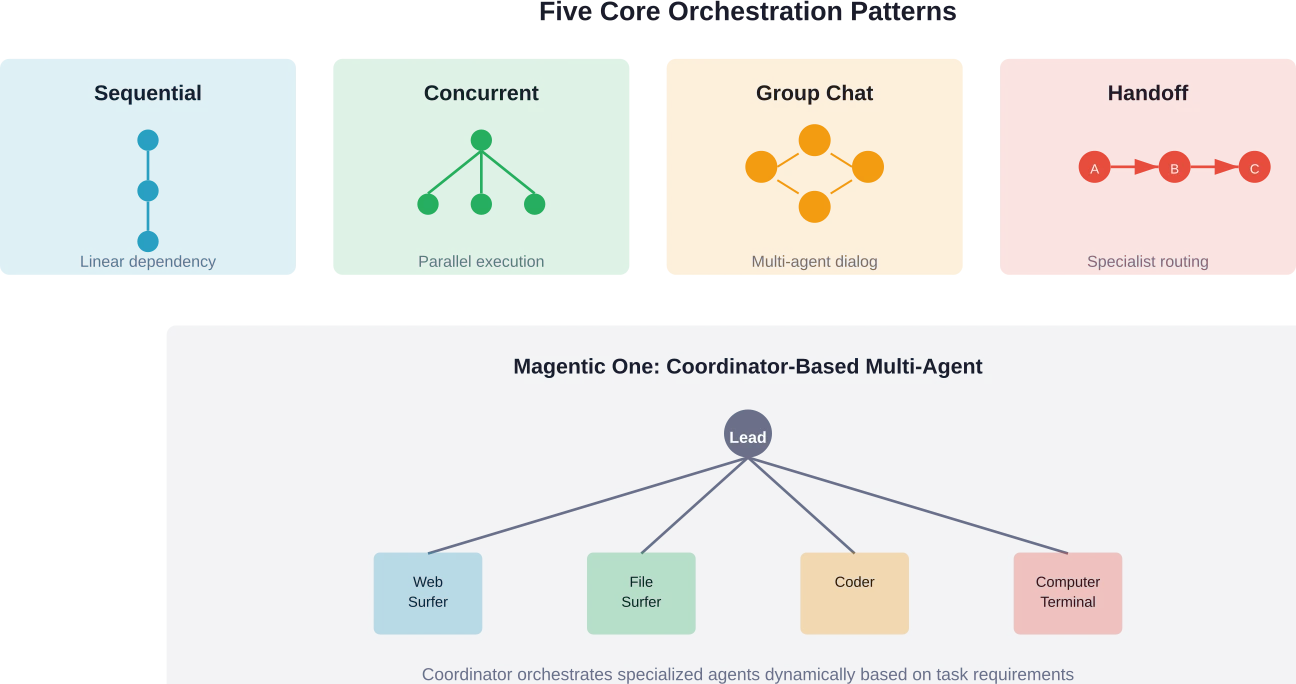
Sequential Orchestration: The Starting Point
Sequential orchestration chains tasks in linear order. Task A completes before task B begins. Simple, predictable, debuggable. This pattern works perfectly for workflows with clear dependencies—retrieve information, then analyze it, then format a response.
When does sequential orchestration make sense? When later steps require outputs from earlier steps. When the workflow maps to a linear process. When debugging and traceability matter more than speed. Most successful agent implementations start here and stay here.
Concurrent Orchestration: Optimizing for Latency
Concurrent orchestration parallelizes independent tasks. Need weather data, stock prices, and news headlines? Fetch them simultaneously rather than sequentially. This pattern reduces total latency from sum of task durations to maximum of individual task durations.
The tradeoff? Complexity in error handling and result aggregation. When one parallel branch fails, how does the system respond? Strong concurrent implementations include timeouts, partial result handling, and clear aggregation logic.
Group Chat: Multi-Agent Collaboration
Group chat orchestration enables multiple specialized agents to discuss and solve problems collaboratively. One agent proposes a solution. Another critiques it. A third synthesizes the discussion into action. This pattern mirrors how human teams tackle complex problems.
Research on agentic frameworks shows group chat patterns excel at problems requiring diverse expertise or perspectives. But they introduce substantial complexity—managing turn-taking, preventing infinite loops, and synthesizing coherent outputs from multi-agent discussions.
Handoff and Magentic Patterns
Handoff orchestration routes tasks sequentially between specialized agents based on task type. A triage agent analyzes the request, then hands it off to the appropriate specialist—sales questions go to the sales agent, technical questions to the technical agent.
Magentic orchestration (popularized by Microsoft's Magentic One framework) uses a central orchestrator agent that dynamically plans, assigns tasks to specialist agents, and synthesizes results. The orchestrator maintains the overall task state while specialists focus on narrow expertise.
When Agents Are Overkill—And When They're Essential
Here's what most architecture diagrams don't tell developers: agents aren't always the answer. In fact, they're often the wrong answer. Before diving into complex agentic systems, consider whether deterministic workflows suffice.
Can task flow be mapped in advance? Use a state machine or workflow engine. Are responses template-driven with minimal variation? Use structured prompt engineering without agent scaffolding. Is latency critical and unpredictability unacceptable? Stick with conventional logic.
Agents introduce non-determinism, latency, cost, and debugging complexity. They shine when tasks genuinely require planning, adaptation, and multi-step reasoning in environments where paths can't be predetermined.
|
Scenario |
Use Agent? |
Why |
|---|---|---|
|
Email classification |
No |
Single LLM call with prompt suffices |
|
Customer support triage |
Maybe |
Simple handoff logic often enough |
|
Research synthesis from 20+ sources |
Yes |
Requires planning, retrieval, synthesis |
|
Data entry validation |
No |
Deterministic rules work better |
|
Complex SQL query generation |
Yes |
Benefits from iteration and validation |
|
Appointment scheduling |
No |
State machine handles this cleanly |
|
Scientific literature review |
Yes |
Open-ended exploration and synthesis |
Where Agents Actually Deliver Value
Anthropic's research on building effective agents identifies domains where agentic approaches consistently outperform alternatives. These include tasks requiring iterative refinement, problems where solution paths vary significantly based on intermediate findings, and workflows that benefit from tool use across multiple systems.
AI2's Asta research assistant demonstrates agents excelling at scientific research—a domain combining literature search, data analysis, synthesis, and hypothesis generation. The Deep Research Tulu project (released November 18, 2025) shows agents conducting multi-hour research sessions that produce comprehensive reports rivaling human analyst output.
Similarly, Google DeepMind's AlphaEvolve (announced May 14, 2025) uses agentic workflows to evolve novel algorithms for mathematical and computational problems—tasks requiring creativity, evaluation, and iterative improvement cycles beyond single-prompt solutions.
Memory Architecture: Making Agents Stateful
Stateless agents that forget everything between interactions? Not particularly useful. Memory transforms agents from sophisticated one-shot responders to systems that learn, adapt, and maintain context across extended engagements.
Memory architecture operates across multiple timescales and storage mechanisms. Working memory holds immediate conversation context within the language model's context window—typically 8k to 200k tokens depending on the model. This provides coherence within individual sessions but vanishes when sessions end.
Episodic memory stores specific past interactions and outcomes. When did the user last engage? What tasks succeeded or failed? What preferences did they express? This typically lives in traditional databases with structured schemas optimized for temporal queries.
Semantic memory stores factual knowledge and learned patterns. This layer commonly uses vector databases like Pinecone, Weaviate, or Chroma that enable similarity search over embedded content. When the agent encounters a question, it retrieves relevant past information to augment its response.
The Context Window Problem
Modern language models offer large context windows. The field has evolved significantly, with models like Gemini 3.1 Flash Image supporting up to 1M token input and 64K token output, indicating rapid advancement in context capacity. But longer contexts create problems. Latency increases linearly with context length. Costs scale proportionally. And research shows models struggle with information retrieval from very long contexts.
Effective memory architectures compress and summarize older context while keeping recent interactions verbatim. Rolling summarization condenses older conversation turns into concise summaries. Selective retrieval pulls only relevant past context rather than including everything.
State management for multi-step workflows requires persisting intermediate results, tracking progress, and enabling resume-after-failure. This typically involves database-backed state machines that checkpoint progress at each significant step.
Tool Integration Patterns and Function Calling
Agents without tools can only think—they can't act. Tool integration enables agents to search the web, execute code, query databases, control browsers, and interact with APIs. This transforms agents from conversational interfaces into genuine automation systems.
Modern tool integration relies on function calling—a structured interface where language models output JSON specifying which function to call with what parameters. OpenAI introduced this pattern in 2023, and it's now standard across major providers including Anthropic, Google, and open models.
Here's how it works. Tools get defined upfront with schemas describing their purpose, input parameters, and output format. The language model receives these tool definitions alongside user queries. When the model determines a tool should be used, it outputs a structured function call rather than conversational text.
The orchestration layer parses this function call, executes the actual tool, captures the result, and feeds it back to the language model. The model then continues reasoning with access to the tool's output. This cycle can repeat multiple times as the agent gathers information and takes actions toward its goal.
Designing Effective Tools
Tool design makes or breaks agent reliability. Each tool should be atomic—performing one well-defined operation. Monolithic tools that do multiple things become difficult to reason about and debug. Clear documentation matters enormously since the language model selects tools based on their descriptions.
Input validation and error handling can't be afterthoughts. Tools need to validate parameters, handle edge cases gracefully, and return structured error information that helps the agent recover. Timeout handling prevents hung operations from blocking agent progress.
The MolmoWeb agent from AI2 demonstrates sophisticated tool design for web automation. Rather than exposing dozens of granular browser actions, it provides higher-level tools for navigation, element interaction, and content extraction—each with clear contracts and robust error handling.
Production Architecture Patterns From Real Deployments
Academic papers present idealized architectures. Production systems look messier but more pragmatic. Based on implementation patterns from successful deployments, several architectural principles emerge consistently.
Start simple and add complexity only when measurements justify it. The most successful teams begin with sequential orchestration, minimal memory, and a handful of well-designed tools. They measure performance, identify bottlenecks, and add architectural complexity selectively.
Observability isn't optional. Production agents need comprehensive logging of every reasoning step, tool invocation, and state transition. This creates the audit trail necessary for debugging non-deterministic systems. Traces that connect user requests through multiple agent steps to final outcomes prove invaluable.

Handling Failure Modes
Language models hallucinate. APIs time out. Tool executions fail. External services rate-limit requests. Production architectures need robust error handling at every layer.
Circuit breakers prevent cascading failures when external dependencies degrade. After N consecutive failures calling a tool, the circuit opens and fast-fails subsequent attempts until a cooldown expires. This prevents wasted latency and allows graceful degradation.
Retry logic with exponential backoff handles transient failures. But retries need careful tuning—too aggressive and they amplify load on struggling services, too conservative and user experience suffers. Idempotency matters enormously since retries can cause duplicate operations.
Fallback strategies provide alternative paths when primary approaches fail. Can't access the search API? Fall back to cached results or a secondary provider. Model outputs invalid JSON? Prompt again with the error and ask for correction. Tool execution times out? Return partial results rather than complete failure.
Security and Compliance Considerations
Agents that execute code, query databases, and access external APIs create substantial security surface area. Input sanitization prevents prompt injection attacks where malicious users manipulate agent behavior through crafted inputs. Tool access controls limit which operations agents can perform.
PII handling requires special attention since agents often process sensitive user data. Logging systems need to redact personal information. Memory stores need encryption at rest. Access controls need proper scoping. Audit trails need comprehensive coverage of data access patterns.
NIST's AI Risk Management Framework provides guidance for managing AI system risks in production environments. The framework emphasizes transparency, accountability, and continuous monitoring—principles that apply directly to agent architectures handling sensitive operations.
Evaluating Agent Performance: Metrics That Matter
Traditional software metrics don't capture agent effectiveness. Agents operate non-deterministically, handle open-ended tasks, and succeed or fail in ways that defy simple binary classification. Evaluation requires different approaches.
Task completion rate measures how often agents successfully achieve their goals. But defining "success" for open-ended tasks proves challenging. Synthesizing research across 20 papers might produce technically correct but practically useless output. Human evaluation often provides the ground truth, but it doesn't scale.
Anthropic's research on measuring agent autonomy (published February 18, 2026) analyzed millions of human-agent interactions to understand how people actually use agents. Research indicates that as users gain experience with autonomous agents, they increasingly enable full auto-approval modes.
Tool use accuracy measures whether agents invoke the right tools with correct parameters. This metric proves easier to evaluate automatically—did the agent call the search function when it should have? Did it pass valid parameters? Did it correctly interpret results?
Latency matters enormously for user experience but creates tension with agent capabilities. More reasoning steps improve decision quality but increase response time. Production systems balance accuracy against latency by setting timeout budgets and optimizing tool execution.
|
Metric Category |
Specific Metrics |
Measurement Approach |
|---|---|---|
|
Task Success |
Completion rate, goal achievement, output quality |
Human eval, automated checks, benchmark suites |
|
Efficiency |
Steps to completion, token usage, tool calls |
Automated logging and analysis |
|
Reliability |
Error rate, crash frequency, timeout percentage |
System monitoring and error tracking |
|
Latency |
End-to-end response time, P50/P95/P99 |
Distributed tracing and metrics |
|
Cost |
Token consumption, API costs, compute hours |
Usage tracking and cost attribution |
|
Safety |
Harmful outputs, privacy leaks, unauthorized actions |
Automated filters plus human review |
Benchmark Suites for Agent Capabilities
Standardized benchmarks enable consistent evaluation across architectures and models. AI2's AstaBench (released August 26, 2025 as part of the Asta initiative) provides comprehensive benchmarking for scientific AI agents—measuring abilities across literature search, data analysis, experimental design, and hypothesis generation.
The AI Agent Systems paper published on arXiv (submitted January 5, 2026) emphasizes that evaluation must span multiple dimensions: capability (can it perform the task?), reliability (does it work consistently?), safety (does it avoid harmful actions?), and efficiency (at what cost?).
Community discussions on platforms like Reddit's r/AI_Agents highlight the gap between academic benchmarks and real-world performance. Agents that excel on standardized tests sometimes struggle with production workloads involving noisy inputs, edge cases, and integration complexity.
Emerging Patterns: Multi-Agent Systems and Specialization
Single generalist agents face inherent limitations. They struggle with tasks requiring deep expertise in multiple domains. Context windows constrain how much information they can process simultaneously. And generalist prompts dilute focus compared to specialist instructions.
Multi-agent architectures partition complex problems across specialized agents, each optimized for specific capabilities. The Agent Design Pattern Catalogue published on arXiv in May 2024 documents how teams decompose systems into cooperating agents with clear responsibility boundaries.
Microsoft Research's Magentic One framework exemplifies this approach. A lead orchestrator agent manages overall task execution while delegating to specialists: a web surfing agent for online research, a file surfing agent for local document analysis, a coder agent for programming tasks, and a computer terminal agent for command execution.
This specialization enables several advantages. Individual agents use focused prompts that improve task-specific performance. Specialists can employ different underlying models—expensive frontier models for complex reasoning, faster cheaper models for routine operations. And failures isolate individual agents rather than cascading through monolithic systems.
Coordination Challenges in Multi-Agent Systems
Multi-agent systems introduce coordination overhead. How do agents communicate? How does the system prevent duplicate work? How do multiple agents maintain a consistent world state? These questions complicate implementations substantially.
Shared memory provides one coordination mechanism. All agents read and write to common data structures tracking task state, findings, and progress. This works well for small agent teams but creates contention and consistency challenges at scale.
Message passing between agents provides explicit communication channels. Agents send structured messages requesting information, delegating tasks, or reporting results. This creates clearer dependency graphs but requires careful design of message schemas and routing logic.
Research on agentic design patterns from system-theoretic perspectives (submitted January 27, 2026 on arXiv) emphasizes that multi-agent coordination requires formal frameworks specifying agent responsibilities, communication protocols, and conflict resolution mechanisms. Ad-hoc coordination leads to emergent complexity that becomes unmaintainable.
Building Your First Agent: Practical Starting Points
Enough theory. How should teams actually start building agents? Based on patterns from successful implementations, here's the pragmatic path that minimizes complexity while establishing solid foundations.
Start with a simple sequential orchestration handling a narrow, well-defined task. Choose a problem where multi-step reasoning provides clear value but the workflow has predictable structure. Email triage, research summarization, or structured data extraction all work well as starting points.
Build the orchestration layer first before worrying about complex memory systems. Get the basic loop working: accept user input, invoke the LLM with appropriate context, parse the response, take action, return results. Instrument everything with logging. Manual observation during early development provides invaluable insights.
Add tools incrementally. Start with one or two high-value tools that enable meaningful capabilities—perhaps web search and code execution. Make each tool robust with comprehensive error handling before adding more. Tool reliability matters far more than tool quantity.
Common Pitfalls to Avoid
Don't over-engineer the first version. Complex frameworks and abstractions create premature optimization. The most successful teams build simple, imperative orchestration code that's easy to understand and debug. Abstraction layers can wait until patterns emerge.
Don't skip observability. Without comprehensive logging and tracing, debugging non-deterministic agent behavior becomes nearly impossible. Log every LLM call with full prompts and completions. Log every tool invocation with parameters and results. Log every state transition. Storage is cheap; debugging time is expensive.
Don't ignore prompt engineering fundamentals. Agent architectures amplify prompt quality—good prompts enable reliable behavior, poor prompts create unpredictable chaos. Invest time crafting clear system instructions, useful examples, and structured output formats.
Don't deploy without rate limiting and cost controls. Agents can generate runaway loops that consume thousands of API calls in minutes. Budget limits, maximum iteration counts, and circuit breakers aren't optional—they're essential safeguards.
![]()
Make Your AI Agent Architecture Usable In Real Workflows
A clean architecture diagram doesn’t guarantee anything in production. Issues usually appear when agents need to access live data, handle permissions, or interact with multiple services at once.
OSKI Solutions helps structure that layer properly. They build the backend, set up integrations, and make sure agents can operate inside existing systems without constant fixes. The focus is on stability and clear logic between components, not just design.
If you’re working on an AI agent architecture, it’s worth going through it with OSKI Solutions before moving further.
AI Agent Architecture Diagram
Visualize how an AI agent processes input, reasons through tasks, uses tools, accesses data, and delivers outputs through a coordinated workflow.
The Future of Agent Architectures
Agent architectures continue evolving rapidly as foundation models improve and deployment patterns mature. Several trends appear likely to shape the next generation of agentic systems.
Specialized models optimized for agentic workloads will likely outperform general-purpose models at specific agent tasks. Models trained specifically on tool use, planning, and iterative refinement could offer better reliability and efficiency than frontier models that prioritize conversational abilities.
Tighter integration between reasoning and execution will reduce the separation between "thinking" and "acting" that characterizes current architectures. Systems that learn from execution outcomes to improve future planning represent a path toward more capable agents.
Standardization of agent protocols and tool interfaces would reduce fragmentation. Currently, every framework defines its own abstractions for tools, memory, and orchestration. Convergence toward common interfaces would enable better interoperability and knowledge sharing.
Research from organizations like Google DeepMind on systems like SIMA 2 and AlphaEvolve demonstrates agents tackling increasingly complex, open-ended problems. As capabilities expand, architectures will need stronger safety guarantees, better alignment mechanisms, and more robust oversight systems.
Key Takeaways for Agent Architecture Design
Designing effective agent architectures requires balancing capability against complexity, autonomy against reliability, and generality against specialization. The patterns that work share common characteristics.
Start simple and measure before adding complexity. Sequential orchestration with basic memory and a few robust tools handles more use cases than teams expect. Complexity should emerge from measured needs, not anticipated requirements.
Observability and error handling aren't optional extras—they're foundational requirements. Non-deterministic systems demand comprehensive instrumentation to enable debugging, evaluation, and continuous improvement.
Tool quality matters more than quantity. Five well-designed, thoroughly tested tools with robust error handling outperform twenty brittle tools that work 80% of the time. The weakest tool determines system reliability, not the strongest.
Agent architectures should optimize for the 80% case, not edge cases. Build deterministic paths for common workflows and reserve agent reasoning for genuinely unpredictable scenarios. This hybrid approach delivers better latency, cost, and reliability than pure agentic systems.
Frequently Asked Questions
What's the difference between an AI agent and a simple LLM chatbot?
AI agents combine language models with planning, memory, and tool usage to complete multi-step tasks autonomously. Chatbots mainly handle conversations and do not typically plan or execute actions beyond generating text.
Do I need a framework like LangGraph or AutoGPT to build agents?
No. Many effective agent systems are built using simple orchestration patterns. Frameworks can help with scaling and structure but are not required for initial development.
How do I prevent my agent from getting stuck in infinite loops?
Use safeguards such as iteration limits, timeouts, cost budgets, loop detection logic, and idempotent tools to prevent repeated actions without progress.
What's the best way to handle memory for agents that need long-term context?
Use layered memory: short-term context within prompts, semantic memory via vector databases, and structured storage for historical interactions. Apply summarization and selective retrieval to manage scale.
How should I evaluate whether my agent architecture is working effectively?
Track metrics such as task completion rate, latency, cost per task, and error rates. Combine automated metrics with human evaluation to assess performance and reliability.
When should I use multi-agent architectures versus single agents?
Start with a single agent. Use multi-agent systems when tasks require specialization, multiple expertise domains, or when performance improvements justify added complexity.
How do I secure agents that have access to sensitive data or privileged actions?
Apply strict access controls, input validation, logging, data encryption, sandboxing, and human approval for critical actions. Follow established frameworks like NIST AI Risk Management for best practices.
Conclusion: From Architecture to Implementation
AI agent architecture diagrams provide mental models for building systems that reason, plan, remember, and act. But diagrams alone don't ship working software. The path from architecture to production requires pragmatic engineering—balancing theoretical elegance against operational reality.
The most successful agent implementations share common traits. They start simple with sequential orchestration and basic capabilities. They instrument everything for observability. They invest heavily in robust tool design and error handling. And they measure continuously, adding complexity only when data justifies it.
As foundation models continue improving and deployment patterns mature, agent architectures will evolve. But the fundamental principles remain: separation of concerns across reasoning, orchestration, memory, and tools. Explicit error handling at every layer. Comprehensive logging for debugging non-deterministic behavior. And relentless focus on the simplest architecture that solves the actual problem.
Whether building research assistants that synthesize scientific literature, automation systems that handle complex workflows, or specialized agents that solve domain-specific problems—the architecture patterns covered in this guide provide foundations for production-ready systems. Start building. Measure results. Iterate based on data. And remember that the best architecture is the simplest one that works.






